
How search engines work ?!
Understanding how search engines work is the first step to being found by your customers through organic searches.
Key Points
- The spider software crawls the web looking for new pages to collect and add to the search engine indices.
- The index software catches everything the Spider can throw at it.
One of the most frequently asked questions from website owners is,
"Why can't my site be found on Google?" They know it's important to
appear in search engine results but they just don't know why it doesn't
happen to them. Ken McGaffin gives this introduction to search engines in Part 1 of Wordtracker's Keyword Basics series
Website owners may well be in awe of the 'black arts' of search engine optimization
or puzzled by the complexity of it all. If they're unlucky they will
have paid out money to some snake oil salesman guaranteeing to get them
to the top of Google's search rankings in 48 hours - and been sorely
disappointed with the lack of traffic that results.
Most search engine optimizers are highly ethical, professional people but they do tend to keep their cards close to their chest.
The big secret is there is no big secret

It's true: the 'big secret' of search engine optimization is that there is no big secret.
It is all about understanding what is going on behind the scenes,
followed by the hard work and attention to detail that are common to
many business activities.
Inside the guts of a search engine
Let's take a simple look at a search engine. There are three pieces
of software that together make up a search engine: the spider software,
the index software and the query software.
If you understand what these three do, then you have the foundation for getting your website to the top of the search engines.
Here's what the three types of software do:
The spider software 'crawls the web looking for new pages to collect and add to the search engine indices'.
This is a metaphor. In reality, the spider doesn't do any 'crawling'
and doesn't 'visit' any web pages. It requests pages from a website in
the same way as Microsoft Explorer, or Firefox or whichever browser you
use requests pages to display on your screen.
The difference is that the spider doesn't collect images or
formatting - it is only interested in text and links AND the URL, (for
example, http://www.Unique-Resource-Locator.html) from which they come.
it doesn't display anything and it gets as much information as it can is
the shortest time possible.
Since the spider doesn't collect images, it doesn't take notice of
Flash intros or colorful pictures. So, make sure your images, logo or
videos are identified by a text 'alt tag,' or the spider will ignore
them and they will not have value in the search engines.
The index software catches everything the spider can
throw at it (yes, that's another metaphor). The index makes sense of
the mass of text, links and URLs using what is called an algorithm - a
complex mathematical formula that indexes the words, the pairs of words
and so on.
Essentially, an algorithm analyzes the pages and links for word
combinations to figure out what the web pages are all about - in other
words, what topics are being covered. Then, scores are assigned that
allow the search engine to measure how relevant or important the web
pages (and URLs) might be to the person who is searching. While each of
the major search engines (like Google, Yahoo or Bing) has their own
secret algorithm for scoring, they are all using the information a
spider collects.
And of course the index software records all of this information and makes it available.
The spider takes the information it has gathered about a web page and
sends it to the index software where it is analyzed and stored.
When someone types chocolate into the query box on a search engine page (such as Google), then it's time for the query software to go to work.
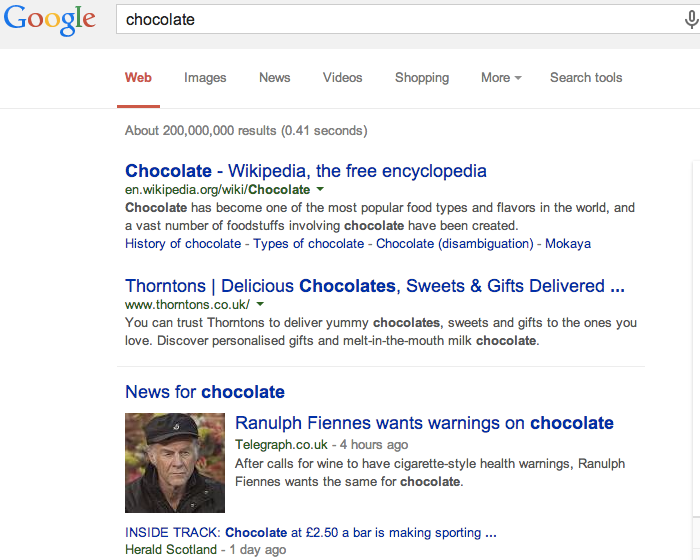
The query software is what you see when you go to a
search engine - it is the front end of what everybody thinks of as a
search engine. It may look simple but the query software presents the
results of all the quite remarkable spider and index software that works
away invisibly on our behalf.
So, when you type in your search words and hit search, then the
search engine will try to match your words with the best, most relevant
web pages it can find by 'searching the web'.
But this too is a metaphor and perhaps the most important one.
The query software doesn't actually search the web - instead, it
checks through all the records that have been created by its own index
software. And those records are made possible by the text, links and URL
material the spider software collects.
What you need to understand about search engines
That is it. What you need to understand is that the search engine has
done all the hard work of collecting, analyzing and indexing web pages,
BUT it only makes that information available when someone does a search
by entering words in the search query box and hitting the return key.
The words people use - what words they type into the query box - when
they search will therefore determine the results the search engine
presents. So search engine optimizers want to know the words people use
when they search - we call them keywords (that might sound fancy but
keywords are only 'the words people use when they search'.)
And that's what Wordtracker provides - information about the words
people use when they do a search. Use keywords in the text (called
'website copy') on your web pages and you will prosper: ignore them and
your online business will surely perish.
Get a free 7-day trial
A subscription to Wordtracker's premium Keywords tool will help you to:
- Generate thousands of relevant keywords to improve your organic and PPC search campaigns.
- Optimize your website content by using the most popular keywords for your product and services.
- Research online markets, find niche opportunities and exploit them before your competitors.
Take a free 7-day trial of Wordtracker’s Keywords tool
